As the following content is primarily directed towards an international audience, it constitutes an English contribution.
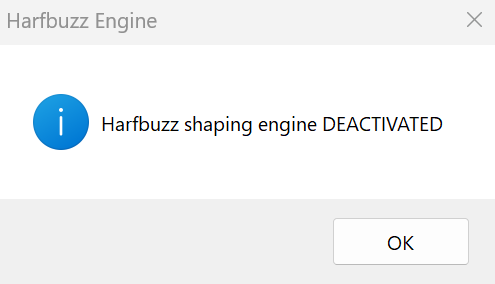
Rainer Klute from InDesign-Sprechstunde drew my attention to a small problem with text break shifts caused by the new default shaping engine Harfbuzz in InDesign CC 2024. This affects only text with south east asian scripts. If you face issues with old documents in InDesign you can simple go back to the old shaping engine. To achieve this task, Adobe put a scripting solution online. To streamline the process and eliminate the need for copy-pasting as suggested, I’ve developed a downloadable solution that functions as a unified script capable of seamlessly switching between both states.
Vor ein paar Tagen erschien das Minor Update InDesign 18.2. Unter Fixed Issues versteckt sich der Hinweis auf die Deaktivierung der Type 1 Schriften:
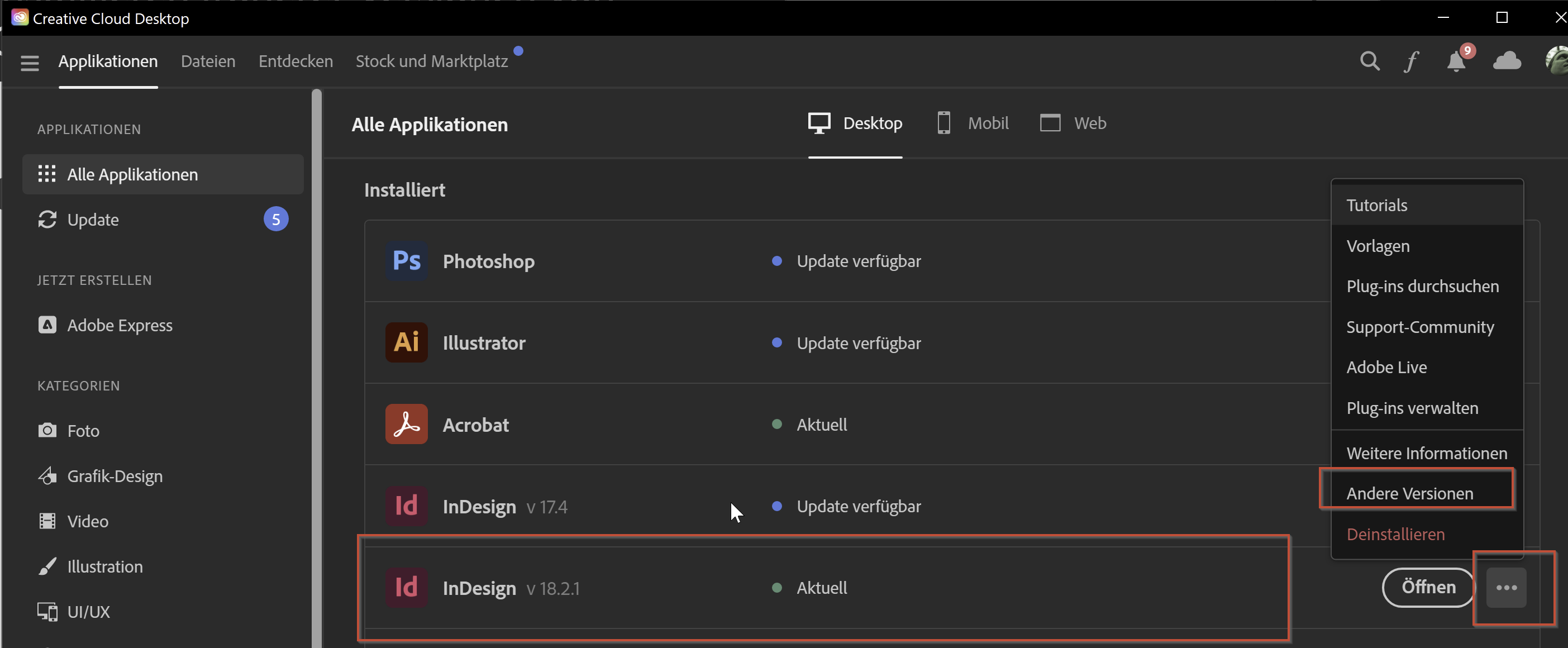
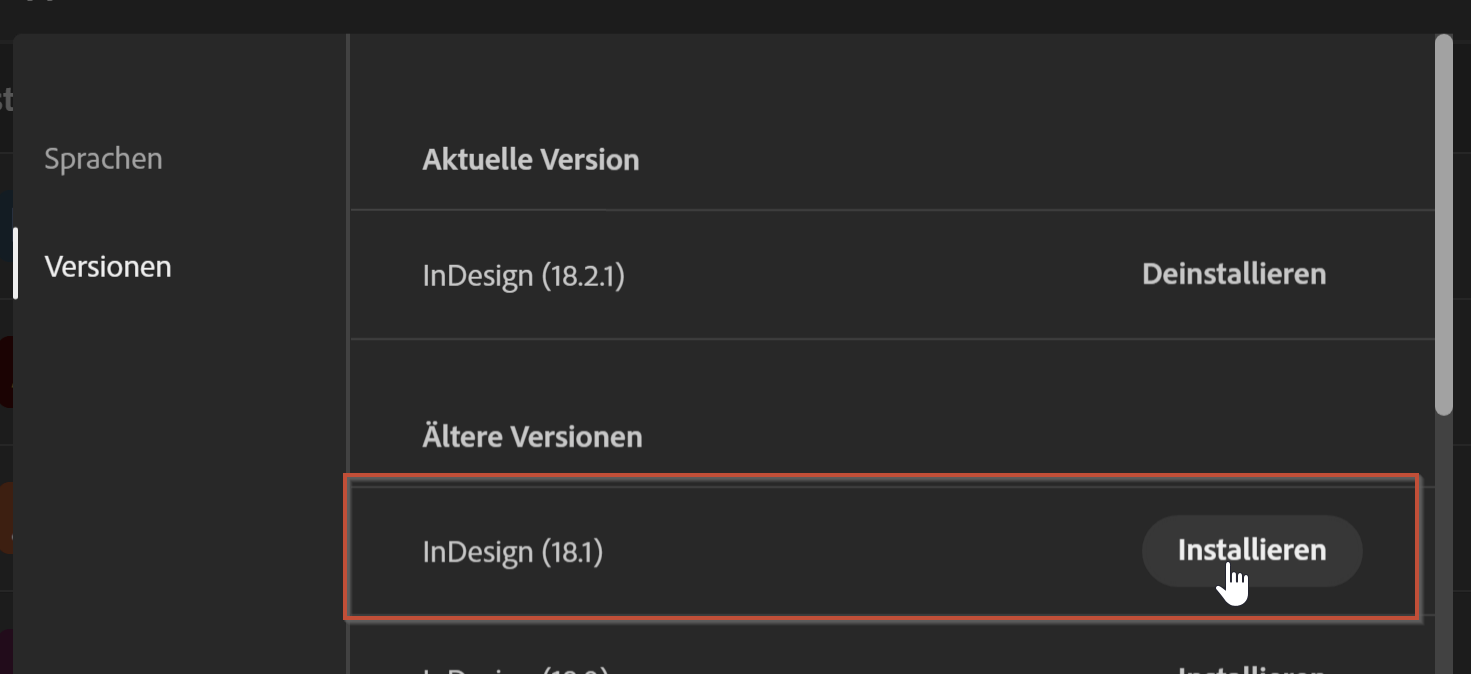
Einige meiner Kunden sind nun überrascht. Das Thema selber ist klar, die Uralt-Schriften müssen aktualisiert werden. Das kann ggfs. auch via Skript geschehen. Aber zur schnellen Abhilfe könnt ihr via Creative Cloud App euer InDesign auch nochmal downgraden:
Bitte trotzdem zeitnah das Thema angehen, denn auf der Version 18.1 wollt ihr natürlich nicht stehen bleiben.
Bevor es aber losgeht, ein Lesetipp: Marc Autret hat gerade in einem Blogbeitrag auf indiscripts.com die aktuellen Ressourcen zum InDesign-UXP-Scripting zusammengestellt.
Nach den ersten UXP-Schritten möchte ich nun das UXP Developer Tool für das Debugging von Skripten vorstellen. Wer noch das veraltete ExtendScript Toolkit bzw. das nachfolgende Plugin für Visual Studio Code kennt, wünscht sich vermutlich die gleiche Anbindung für die Entwicklung von UXP-Skripten. Visual Studio Code selbst hat bereits einen integrierten JavaScript-Debugger, der für V8-Engine-Kontexte funktioniert. Rein technisch gesehen müsste Visual Studio Code also in der Lage sein, UXP sofort zu debuggen. Das klappt aber (noch?) nicht. Leider habe ich auch keine Informationen, ob diese Anbindung geplant ist.
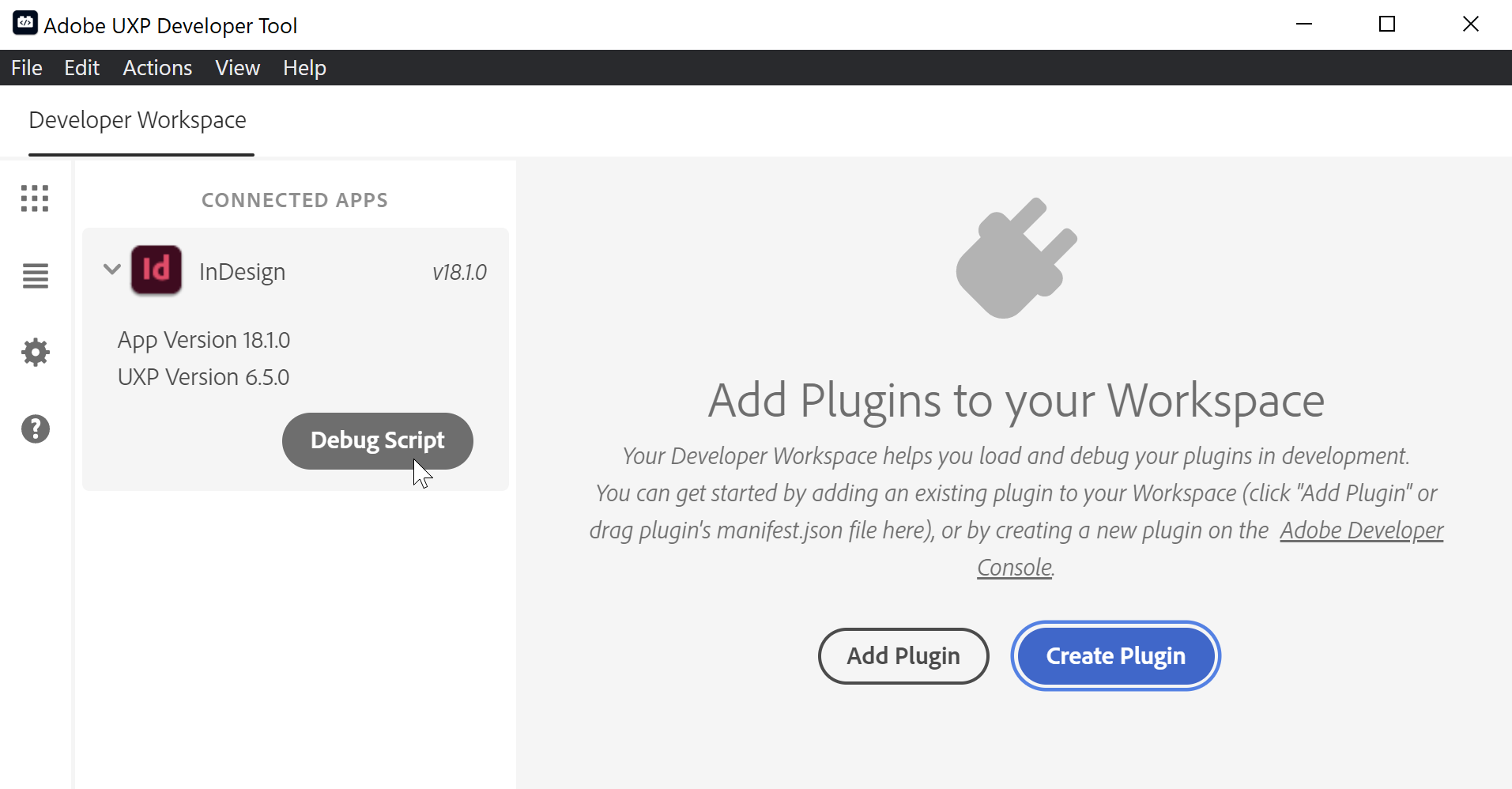
Stattdessen bietet Adobe das sogenannte UXP Developer Tool (UDT) an. Der Fokus des Tools ist die Verwaltung von Plugins, wie sie bereits für Photoshop oder Adobe XD entwickelt werden können. InDesign unterstützt aktuell aber nur UXP Scripting, d.h. wir benötigen vom UDT auch nur den Bereich zum Debugging von Skripten.
Installation
Das Adobe UXP Developer Tool kann über die Adobe Creative Cloud-Anwendung installiert werden. Die Systemvoraussetzungen sind vermutlich bei den Meisten erfüllt. Eine ausführliche Anleitung findet ihr bei Adobe. In Kürze:
Creative Cloud Desktop Anwendung starten.
Alle Applikationen auswählen.
In der Liste sollte das UDT auftauchen.
Installieren auswählen.
WICHTIG: Das Adobe UXP Developer Tool benötigt Administratorrechte, um korrekt zu funktionieren. Wenn dein Administrator dir keine erweiterten Rechte einräumt, kannst du dieses Tool nicht verwenden.
Und los…
Nacht der Installation startest du InDesign und dann das UXP Developer Tool. Wenn im Bereich Connected Apps kein Eintrag für InDesign zu sehen ist, überprüfe, ob InDesign auch gestartet ist. In meinen Tests hat das UDT sowohl Photoshop als auch InDesign einwandfrei erkannt.
Das UDT-Fenster
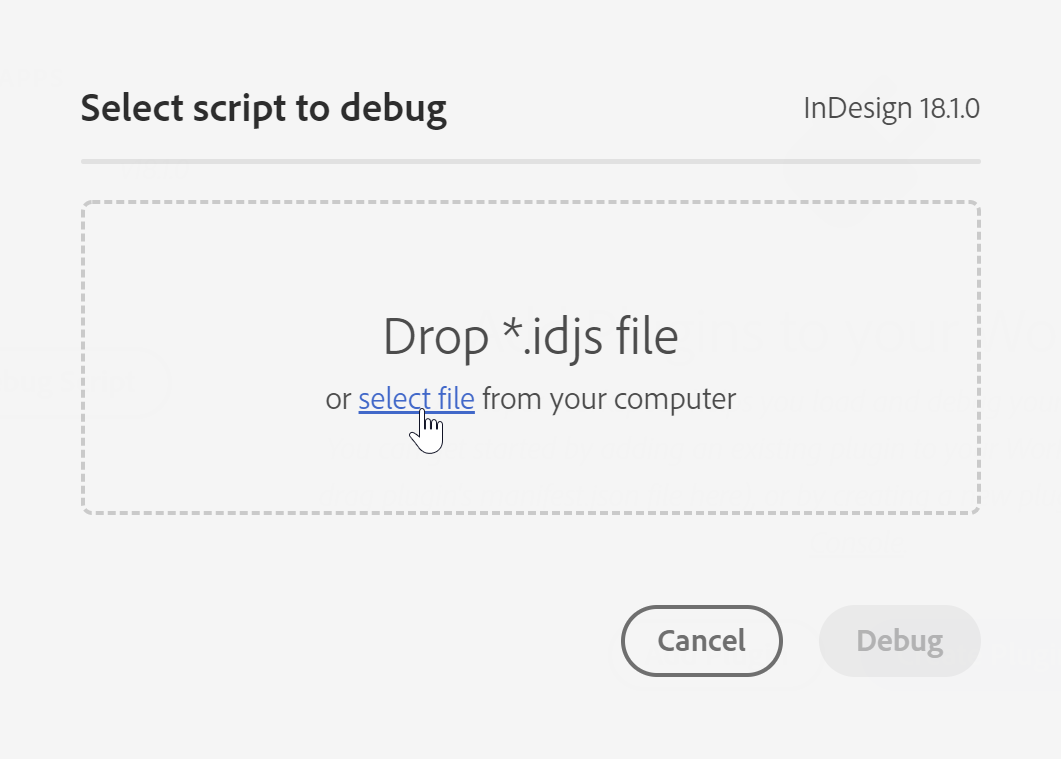
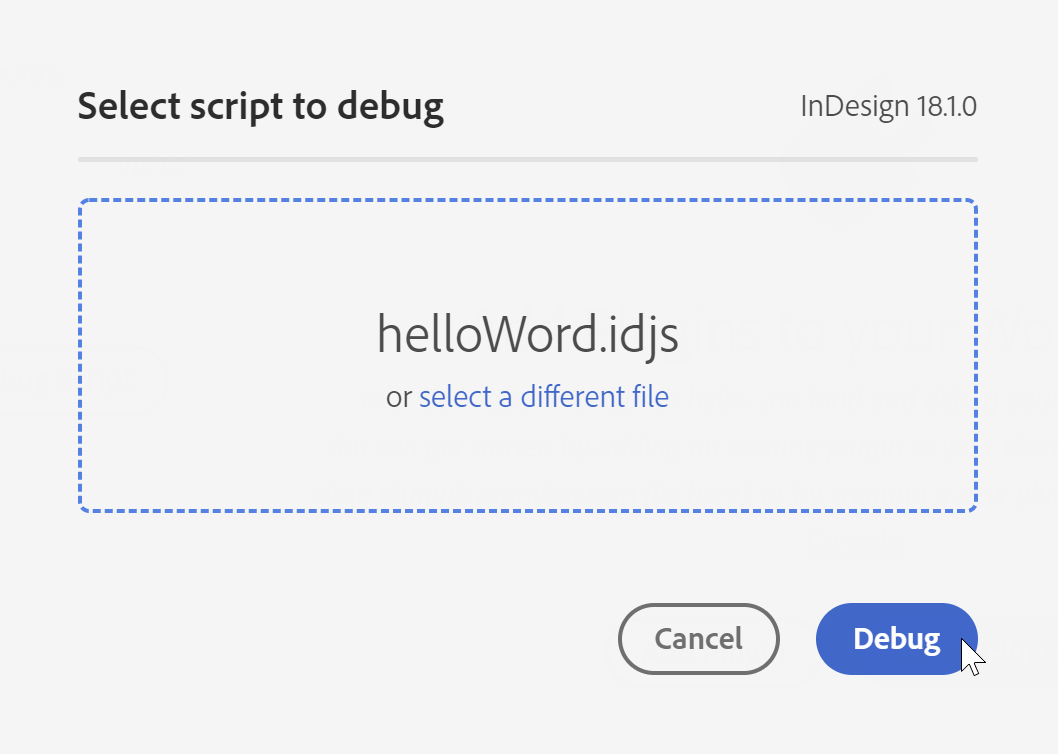
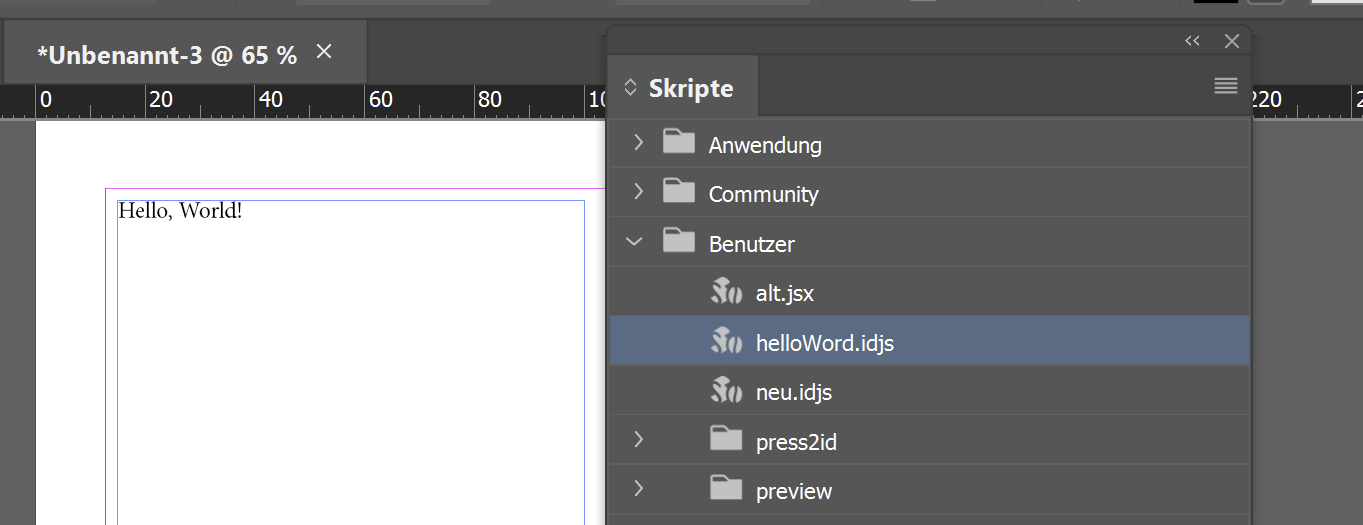
In InDesign 2023 können wir noch keine echten Plugins (mit einem eigenen Bedienfeld) erstellen. Deswegen ist für uns nur der Button Debug Script relevant. Klicke den Button Debug Script und wähle dann das Skript helloWord.idjs aus dem letzten Beitrag oder ein eigenes UXP-Script. Wähle dann den Button Debug.
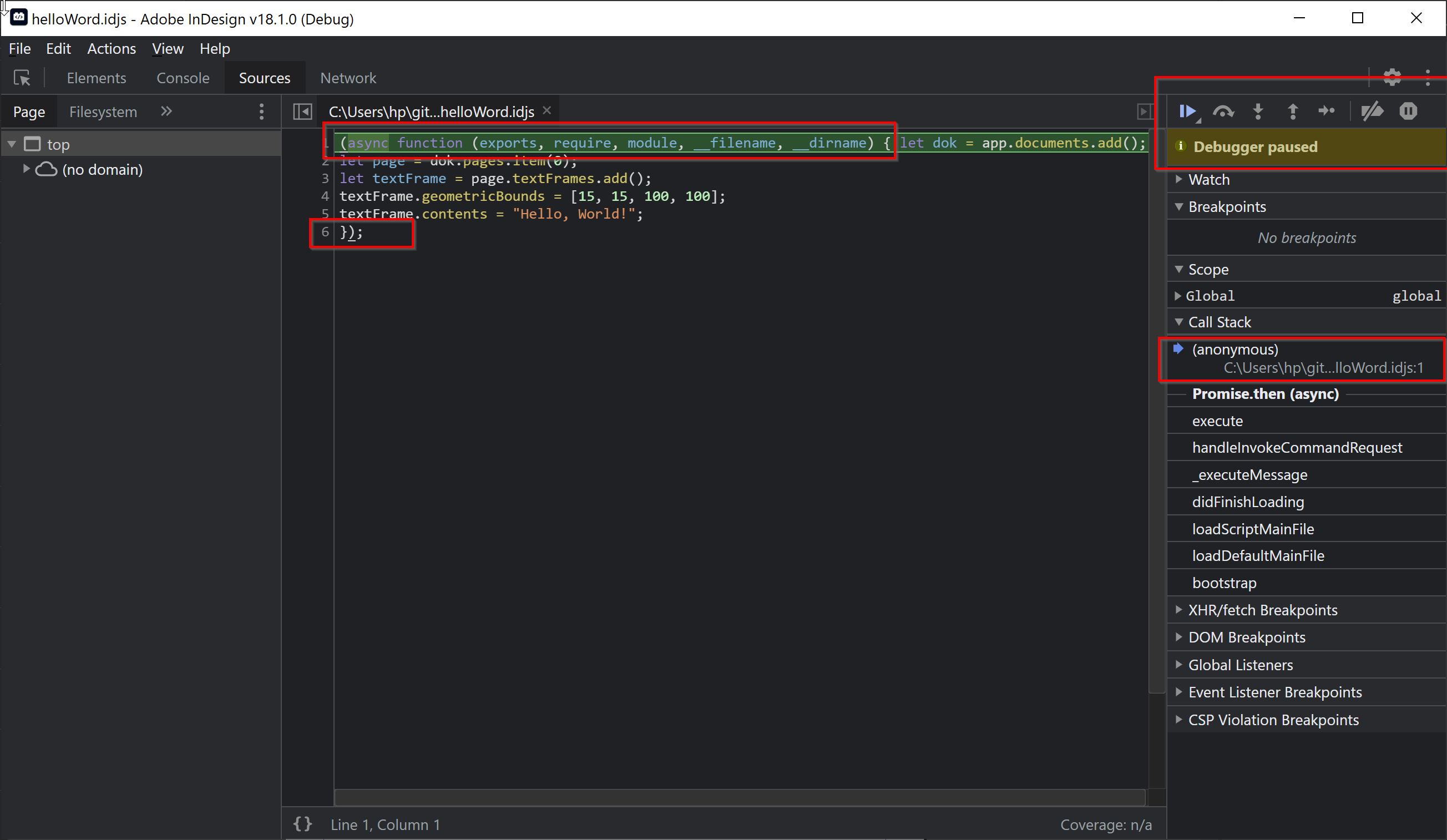
Nun startet der eigentliche Debugger in einem neuen Fenster. Die Ansicht ist dem ein oder anderen vielleicht schon aus der Web-Entwicklung als Chrome Developer Tools bekannt. Für uns ist aber erst einmal nur der Tab Sources relevant. Der Debugger hat das von uns gewählte Skript geladen, aber noch nicht ausgeführt.
Das ausgewählte Skript wird automatisch mit einer asynchronen Funktion umschlossen. Dadurch steht die erste Zeile des Skripts etwas unübersichtlich nach dem Funktionsaufruf, hat aber noch die gleiche Zeilennummer.
(async function (exports, require, module, __filename, __dirname) {
//...
});
Das bedeutet hier zunächst einmal nur, dass InDesign auch während der Debug Session reagiert. Die alten ExtendScript-Skripte waren immer synchron, d.h. während eines Skriptlaufs konnte InDesign nicht angesprochen werden.
Klicke jetzt im rechten Bereich auf den Pfeil Button (oder die Taste F8), um den Debugger zu starten.
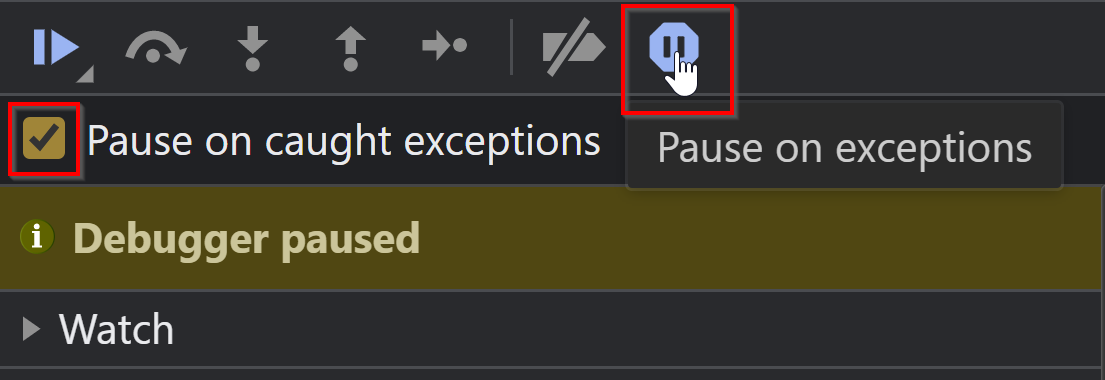
Da wir aber keine Breakpoint gesetzt haben und das Skript keinen Fehler enthält, läuft der Code einfach durch und in InDesign sollte das Dokument mit dem Textrahmen erstellt worden sein. Das Developer-Tools-Fenster wird automatisch geschlossen. Das Gleiche passiert sogar, wenn ein Fehler im Skript enthalten ist. Deswegen empfehle ich dringend, die Default-Einstellungen zu verändern:
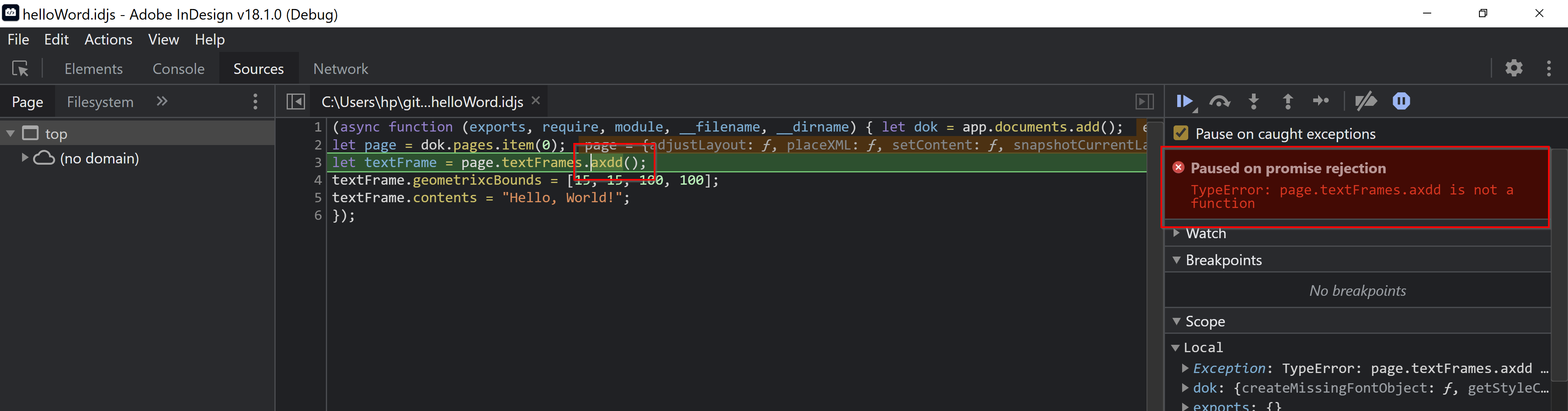
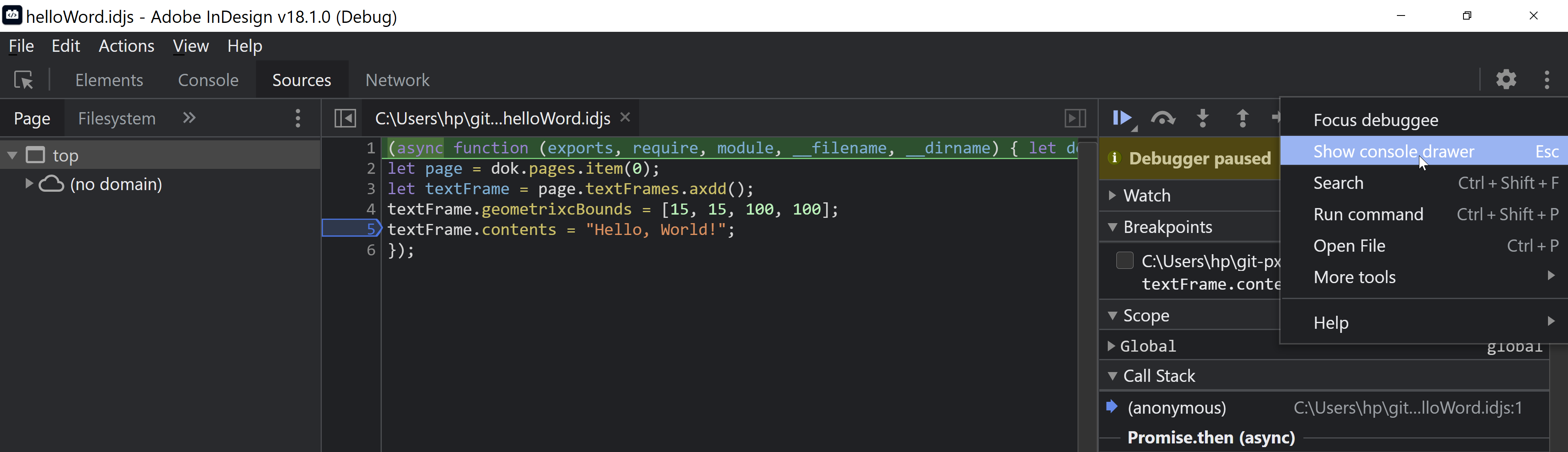
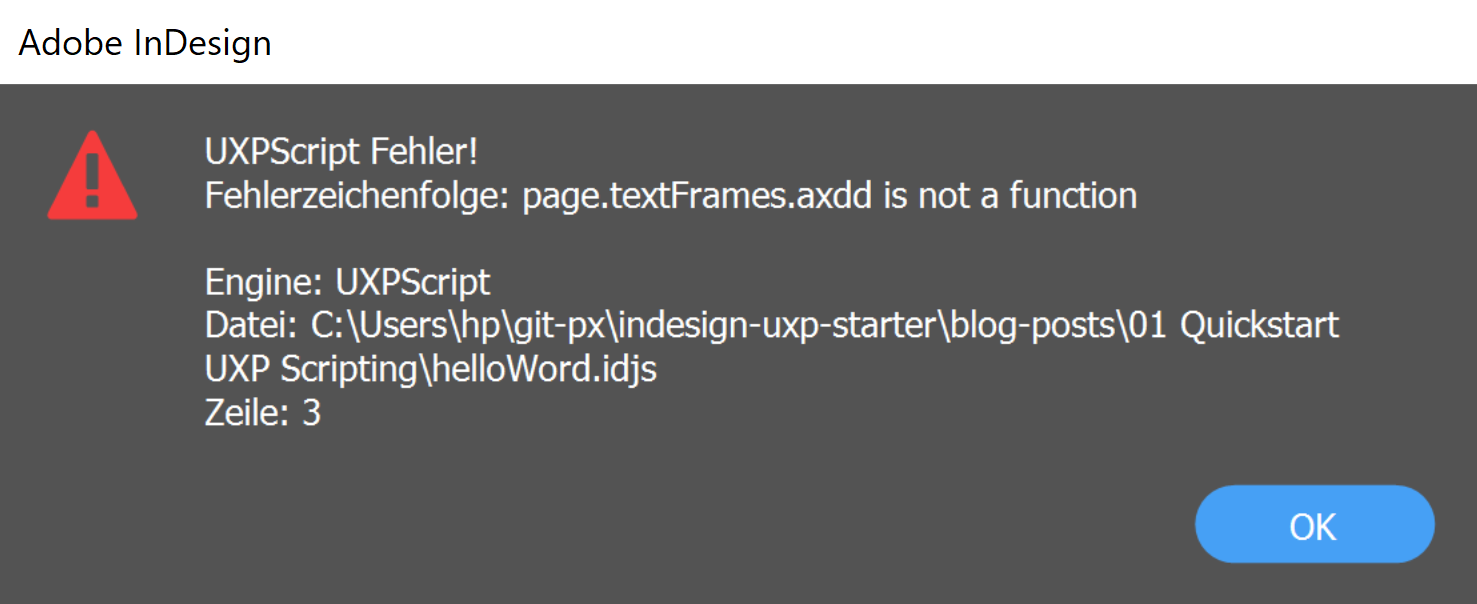
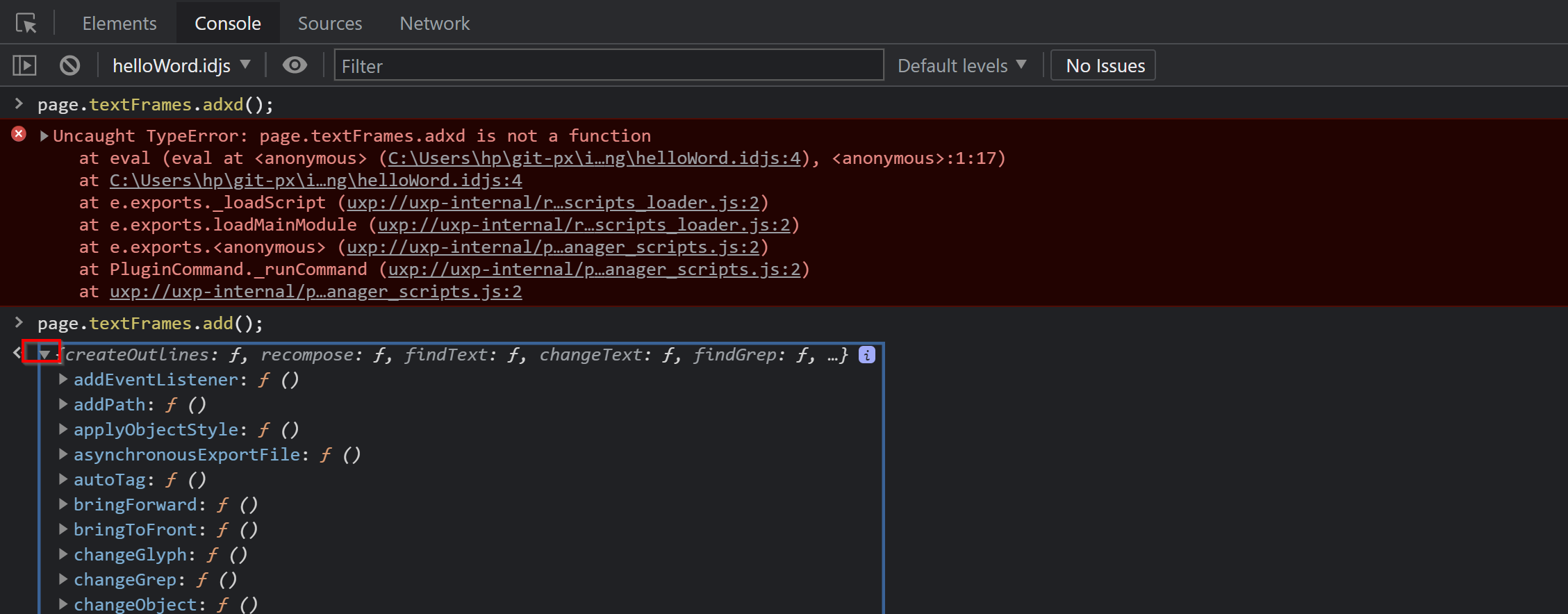
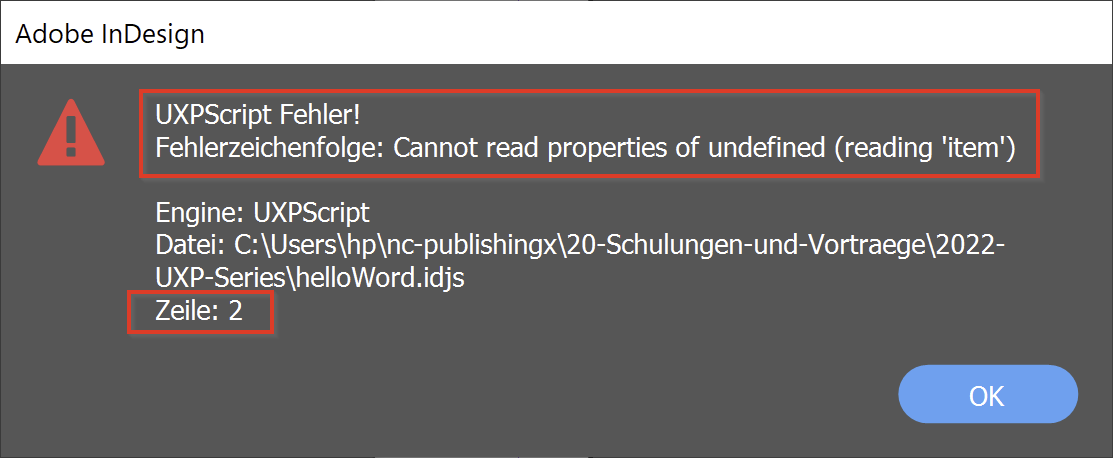
Nur mit dieser Einstellung wird ein möglicher Fehler angezeigt und die Developer Tools bleiben mit der V8 JavavScript Engine von InDesign verbunden. Verändere im Skript helloWord.idjs in Zeile 3 add() zu axdd() und starte eine neue Debug-Session. Nach der Einstellung von Pause on caught exceptions und dem Start des Skripts sollte es dann so aussehen:
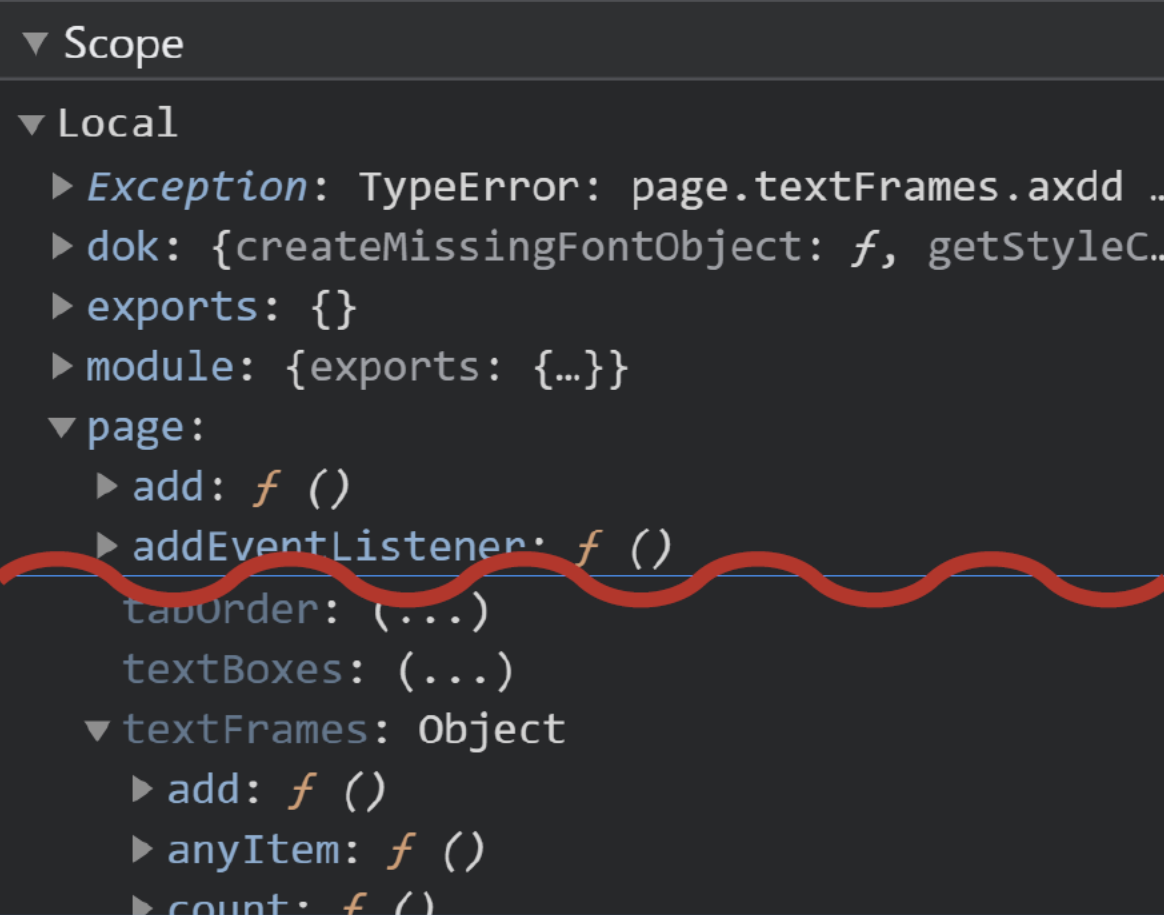
Die Funktion axdd() existiert nicht und wirft, wie zu erwarten, eine Exception. Wir können uns nun auf die Fehlersuche begeben. Als Erstes suchen wir im rechten Bereichs des Fensters unter Scope die möglichen Funktionen der Eigenschaft textFrames:
Hier finden wir alle Eigenschaften und Funktionen und auch die korrekte Schreibweise add(). Leider können wir den Code nicht live korrigieren, sondern müssen zurück in Visual Studio Code (oder einen anderen Texteditor) und die Debug-Session neu starten.
Bevor wir das allerdings erledigen, sollten wir in der Console testen, ob der Befehl funktioniert. Dazu empfehle ich, die Console unterhalb des Sources Tabs einzublenden. Klicke auf das Menü ganz rechts oben und wähle Show console drawer. Alternativ könne ihr auch den Tab Console links neben Sources aktivieren.
Danach erscheint unterhalb des Fensters ein Eingabebereich, in dem man den Befehl page.textFrames.add() ausprobieren kann. Es funktioniert:
Wenn man jetzt das Developer-Tools-Fenster schließt, erscheint die Warnmeldung mit der Exception in InDesign als modaler Dialog. Diesen muss man noch einmal extra wegklicken, sehr nervig.
Weitere Tipps für die Developer Tools
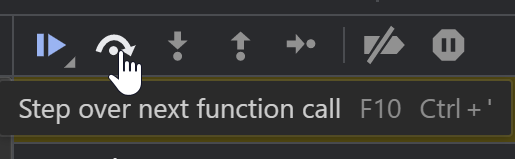
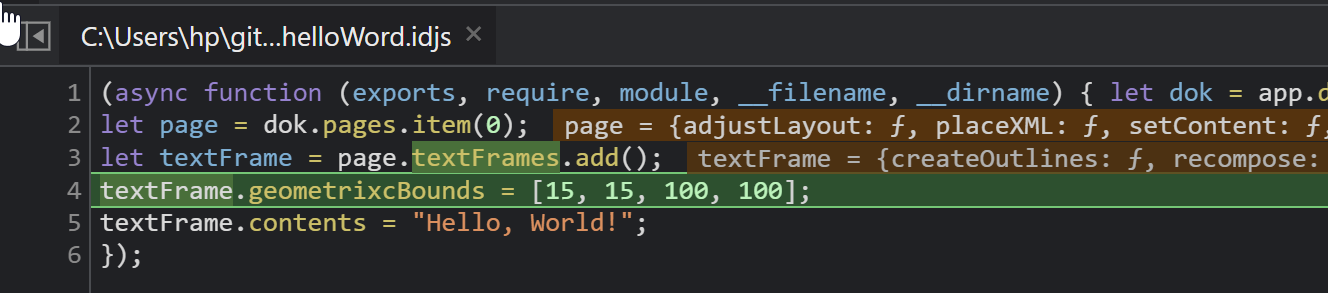
Mit dem Step Over Button bzw. F10 kann man Schritt für Schritt durch den Code schreiten. Die nächste Zeile, die ausgeführt werden wird, ist grün hinterlegt. Im folgenden Beispiel sind Zeile 1 bis 3 bereits ausgeführt: In diesem Zustand ist das Dev-Tools-Fenster mit der V8 JavavScript Engine von InDesign verbunden. D.h. wir können in der Console den Zustand der Variablen zur Laufzeit auswerten.
Nach dem Eintrag page. erscheint ein Autocompletion-Feld mit den möglichen Eigenschaften des Objekts. Das gefällt mir super und ist eine tolle Verbesserung. Wenn man ein den Befehl mit Return bestätigt, erscheint in der Console das Ergebnis. Hier ein absichtlich eingetragener Fehler und der zweite, korrekte Versuch:
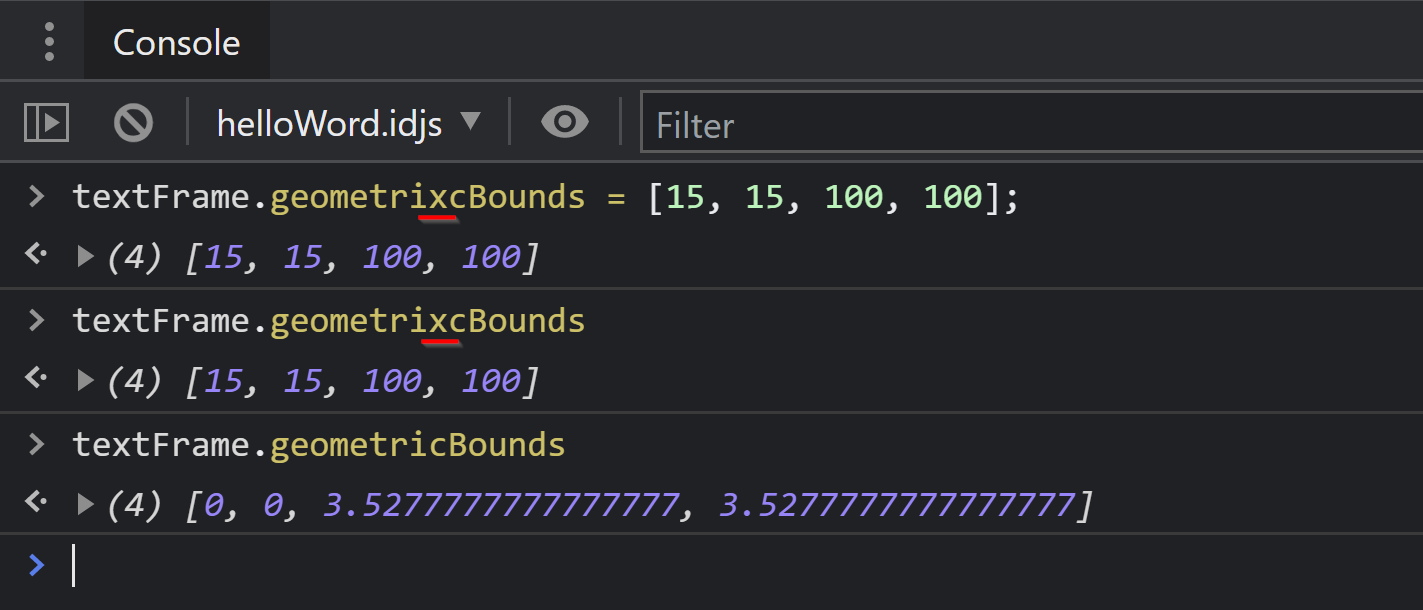
Beim Experimentieren mit der Console ist mir eine ärgerliche Änderung in UXP aufgefallen. UXP erlaubt die Zuweisung von beliebigen Eigenschaften an ein Objekt. Tippfehler können schnell übersehen werden und Code-Teile werden unerwarteterweise nicht ausgeführt! Schau dir das folgende Beispiel mit der fehlerhaften Eigenschaft geometrixBounds an:
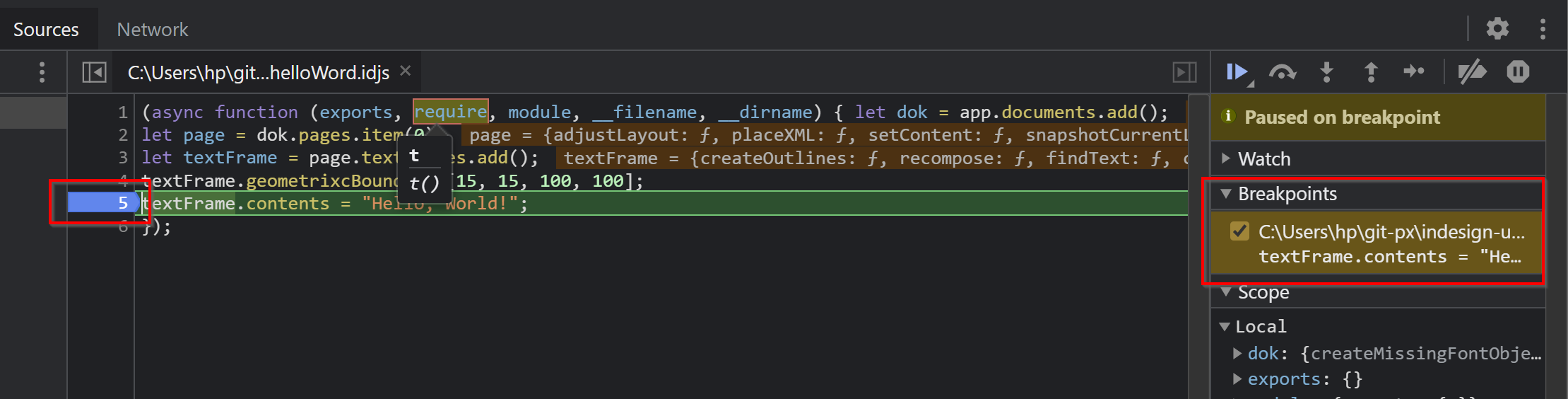
Fehlt eigentlich nur noch ein Breakpoint. Das ist auch ganz einfach: Im Bereich Sources setzen wir diesen vor der Ausführung des Skripts neben die Zeilennummer:
Während das Skript beim Breakpoint zum Halten gekommen ist, kann natürlich wieder der Code inspiziert werden.
Fazit
Alles in allem ist der Prozess noch nicht optimal. Bei jedem neuen Testlauf muss das Skript manuell ausgewählt und gestartet werden! Bei einem Fehler muss das Tool zunächst geschlossen werden und das Skript in einem anderen Editor korrigiert werden. Besser wäre es, wenn man das Skript im Dev Tool korrigieren und direkt neu starten könnte. Wie üblich beim Thema UXP: Wir stehen noch am Anfang!
Mit InDesign CC 2023 bekommen wir das lang ersehnte moderne JavaScript. Mit UXP (Unified Extensibility Platform) ist Adobe der nächste große Wurf für die Automatisierung seiner Applikationen gelungen. Nach XD und Photoshop wurde die Technologie in InDesign implementiert. Auch wenn es zunächst nur die reine Script-Variante ist, lässt sich schon die vollständige UXP-Unterstützung mit grafischen Benutzeroberflächen und Bedienfeldern im nächsten großen Release voraussehen.
Genug Zeit also, diesen Blog zu reaktivieren und sich mit der Technologie auseinanderzusetzen. Als Einstieg werde ich ohne ExtendScript Ballast ein kleines Skript in UXP erstellen. Später folgen dann Beiträge zum Entwicklungsworkflow, den erweiterten Möglichkeiten wie z.B. den Netzwerkzugriff und den Unterschieden zur abgelösten ExtendScript-Technologie – maßgebend für die Konvertierung von alten Skripten.
Wichtig an dieser Stelle: ExtendScript wird auch in Zukunft unterstützt! Alte Skripte müssen also nicht konvertiert werden. Es empfiehlt sich viel mehr zunächst kleinere neue Projekte mit UXP zu starten!
Los geht’s
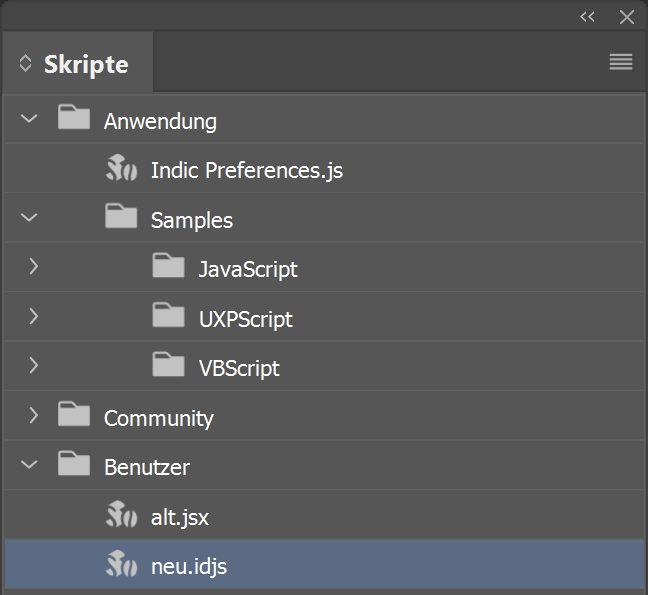
Wir brauchen das aktuellste InDesign CC 2023 (v. 18) und einen Texteditor z.B. Visual Studio Code. Nach dem Start von InDesign siehst du im Skripte-Bedienfeld bei den Beispielskripten bereits die UXPScripts. In meinem Screenshot sind auch die beiden Benutzer-Skripte alt.jsx und neu.idjs installiert;
Entscheidend ist die Dateiendung der Skripte: Mit .idjs startet InDesign das Skript in der UXP-Umgebung, mit .jsx wird die ExtendScript-Engine angeworfen.
Wenn du nicht weißt, wie die Skripte dahinkommen, zur Installationsanleitung hier entlang.
Hello, World!
Okay, ich bin über 40: Ich starte meine Reise immer mit einem Hello, World! Skript.
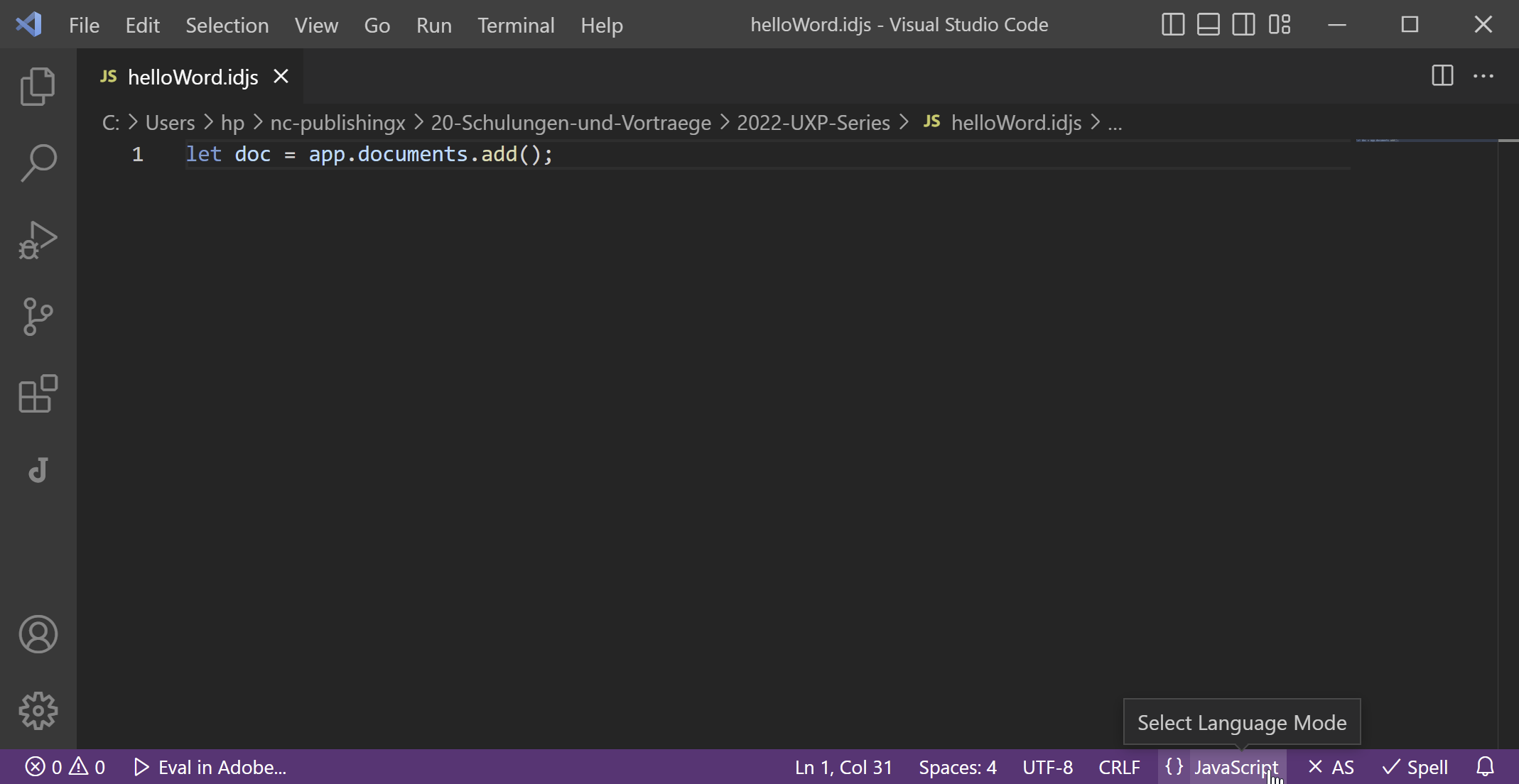
In Visual Studio Code lege ich eine neue Datei helloWord.idjs an. Rechts unten in der Statusleiste empfehle ich den Language Mode JavaScript für eine korrekte Syntaxhervorhebung:
In der ersten Zeile
let doc = app.documents.add();
erstelle ich ein neues Dokument. Leider gibt es noch keine API-Dokumentation, sodass ich aktuell nur auf die ExtendScript-Dokumentation verweisen kann, die aber fast identisch ist. Die Unterschiede werde ich in einem eigenen Beitrag beschreiben.
Für mein Beispielskript möchte ich nun auf der ersten Seite des Dokuments einen Textrahmen erstellen und diesen mit dem Text Hello, World! befüllen.
let dok = app.documents.add();
let page = dok.pages.item(0);
let textFrame = page.textFrames.add();
textFrame.geometricBounds = [15, 15, 100, 100];
textFrame.contents = "Hello, World!";
In der zweiten Zeile wird die erste Seite des Dokuments referenziert (ein InDesign-Dokument hat immer mindestens eine Seite). Auf dieser Seite erstelle ich dann in Zeile 3 einen neuen Textrahmen mit der Methode add(). Der Textrahmen in der Variablen textFrame wird mit der Eigenschaft geometricBounds die Position und Größe zugewiesen. Dazu werden die Koordinaten als Array mit den Werten [y1,x1,y2,x2] übergeben. Schlussendlich wird der Eigenschaft contents der Hallo-Welt-String zugewiesen.
Dieses einfache Programm ist fast identisch mit dem ExtendScript-Pendant. Beachte allerdings die Verwendung von let zur Deklaration der Variablen und die Adressierung der Seite über die Methode ipages.item(0) anstatt über die eckigen Klammern. Auch wenn ich die Abkürzung über die eckigen Klammern immer sehr praktisch fand, waren Sie doch nur ein ExtendScript-Hack der viele Teilnehmer:innen in meinen Schulungen immer auf die falsche Array-Fährte geführt hat.
Nach der Installation im Skripte-Bedienfeld kannst du das Skript wie gewohnt per Doppelklick starten. Das Ergebnis sieht das so aus:
Solltest du dich irgendwo vertippt haben, erscheint ein Warnfenster mit der Zeilennummer und der Fehlermeldung:
Wie man hier auf die Suche geht, zeige ich im nächsten Beitrag zum Entwicklungsworkflow mit dem Adobe UXP Developer Tool.
Wer nicht bis zum nächsten Beitrag warten kann, dem sei die InDesign UXP Scripting Übersicht von Adobe empfohlen. Leider ist diese noch stark verbesserungswürdig!
Am 17. März 2021 um 11 Uhr stehen die Durchführenden in einem kostenlosen Webinar Red und Antwort. Hier kannst du dich anmelden >>
Inhalte des Seminars
Die Möglichkeiten der InDesign-Automation sind schier grenzenlos: Scripting, GREP, Plugins, strukturierte Daten und immer wichtiger: Crossmediale Schnittstellen ins Web.
Was steckt dahinter und wie kannst du es in deiner Praxis einsetzen? Das ist der Schwerpunkt dieses Lehrgangs. Du lernst die Möglichkeiten der Automatisierung und Schnittstellen: Am Ende kannst du dieTechnologien selber einsetzen und Projekte implementieren!
Die wichtigsten Themen werden ausführlich vorgestellt und der jeweilige Nutzen anhand von Praxisbeispielen verdeutlicht: Der Einsatz von regulären Ausdrücken mit GREP, InDesign Skripting mit JavaScript, WordPress und Cloud Publishing sowie XML und Anbindung an Datenbanken am Beispiel von EasyCatalog.
Damit die Projekte auch gelingen, gibt es umfassendes Basiswissen zum Projektmanagement noch dazu!
Wie, wann, wo – wie lange
Geplanter Start: Ende September 2021
Dauer: Zirka 12 Tage + betreutes Praxisprojekt 4 Tage
Für die Schweiz und Österreich: René Theiler/ Tel. +41 31 351 15 11
Für Deutschland: Adeline Anders(data2type GmbH, Heidelberg) / Tel. +49 6221 7391260 bei Fragen zum Inhalt des Lehrgangs Melanie Erlewein (dmpi, Stuttgart) /Tel. +49 711 4 50 44 50 bei Fragen zu der Organisation
InDesign CC 2021 hat einen kleinen fiesen Bug: Wenn ein Dokument aus einer älteren Version geöffnet wird [Umgewandelt], merkt sich InDesign nicht wo die Datei wieder gespeichert werden muss. Beim Speichern öffnet InDesign stattdessen den zuletzt geöffneten Ordner. Das ist natürlich super nervig.
Mit dem Skript addScriptFolderToMenu kann das InDesign-Menü mit eigenen Skripten erweitert werden.
Warum das alles?
Die Verwaltung und die Benutzung von Skripten hat sich für den Anwender von InDesign seit Version 1 nicht geändert. Dreh und Angelpunkt ist dabei die Skripte-Bedienfeld. Die Väter der Idee von addScriptFolderToMenu stellen fest, dass dieser „versteckte“ Zugang einer der Gründe dafür ist, dass die Nutzung der Skripttechnologie vor allem bei Neulingen und technisch wenig versierten Anwendern nur sehr beschränkt erfolgt.
Ziel
Ziel von addScriptFolderToMenu ist es den Zugang zu Skripten und damit deren Anwendung in InDesign zu erleichtern. Auch Anfänger und Gelegenheitsnutzer sollen die Skripte prominent sehen und niederschwellig nutzen können. Seinen besonderen Charme spielt diese Lösung aus, wenn man diese Lösung so konfiguriert, dass mehrere Rechner auf die gleichen Skripte zugreift! So ist sicherzustellen, dass alle Teammitglieder immer alle Skripte im Zugriff haben und auch immer auf gleichem Stand sind. Eine Verteilung von Skripten ist so ein Kinderspiel.
Vorteile
In mehreren InDesign-Versionen nutzen
Wenn das Startupscript in mehreren InDesign-Programmversionen installiert ist, kann man das Menü auch in allen nutzen. So ist es möglich in allen InDesign-Versionen ein Set an Skripten zu nutzen.
Im Team nutzen
Wenn der Ordner für das Menü auf einem Server liegt, ist es möglich, dass das ganze Team mit einem Set an Skripten arbeitet Der Autor dieser Zeilen hat den Ordner in einem G-Drive-Ordner liegen und nutz auf diese Weise das Gleiche Set an Skripten auf mehreren Rechnern.
Nachteil Tastaturbefehle
Sie können den Skripten für das Menü nur dann Tastaturbefehle zuweisen, wenn der Ordner im Skripte-Bedienfeld sichtbar ist. Dann sind die Skripte also sowohl über Menü als auch das Bedienfeld ausführbar.
Vorabinfo: Was ist ein Startupscript
Ein Startupskript liegt in InDesign in einem bestimmten Verzeichnis und wird beim Start des Programms geladen. Damit können verschiedene Szenarien realisiert werden. Unter anderem können, wie in diesem Fall, Menübefehle in InDesign eingefügt werden.
Der schnellste Weg zum richtigen Ordner führt über die Bedienfeld Skripte (Fenster > Hilfsprogramme > Skripte). Dort gibt es die Ordner Anwendungund Benutzer. Mit einem Klick per rechte Maustaste kann man diese im Finder/Explorer öffnen. Es öffnet sich der Ordner Scripts. Wenn es dort keinen Ordner startup scripts gibt, kann man ihn einfach anlegen und Startupskripte hineinlegen
Bestandteile von addScriptFolderToMenu
Startupskript
Das Startupskript addScriptFolderToMenu.jsx gehört, wie oben beschrieben, in das Verzeichnis startup scripts.
Der Ordnerpfad zu den Skripten kann verändert werden. Öffnen Sie das Skript in einem geeigneten Texteditor (z.B. VSCode, Notepad++, …). Sie finden dort die Zeile scriptMenuFolderName: Fügen sie unter diese Zeile den Pfad zum Ordner ein, der zum Skript gehört. Dies kann der gleiche Ordner sein, es kann aber auch ein beliebiger Ordner auf dem Rechner oder im Netzwerk sein.
Wenn Sie den Ordner auf ein Netzwerkverzeichnis legen bedenken Sie, dass sie auf diese Skripte nur zugreifen können, wenn Sie Zugriff auf dieses haben.
Ordner
In den Ordner, der unter scriptMenuFolderName: genannt ist, kann man beliebig viele Skripte oder Ordner ablegen. Diese werden in InDesign unter dem Menüpunkt, der unter scriptMenuName definiert ist, angezeigt.
Namenskonventionen
Die Ordner und Skripte werden alphabetisch sortiert.
A_ordner
B_skript
C_ordner
D_ordner
E_ordner
Es ist jedoch zusätzlich möglich die Namen der Ordner und Dateien mit einer zweistelligen Ziffer gefolgt von einem Underline zum umsortieren zu bringen.
10_Ordner
20_Skript
30_Skript
35_Skript
40_Ordner
Skriptnamen Metadaten
Die Namen von Skripten, vor allem, wenn man die kostenlosen aus dem Internet herunterlädt, sind manchmal kryptisch. Man kann die Namen, die im Menü erscheinen jedoch manipulieren. Dazu öffnen Sie das Skript und fügen in die erste Zeile des Skriptes //SCRIPTMENU: ein gefolgt von dem Namen, der im Menü erscheinen soll.
Skriptmenü
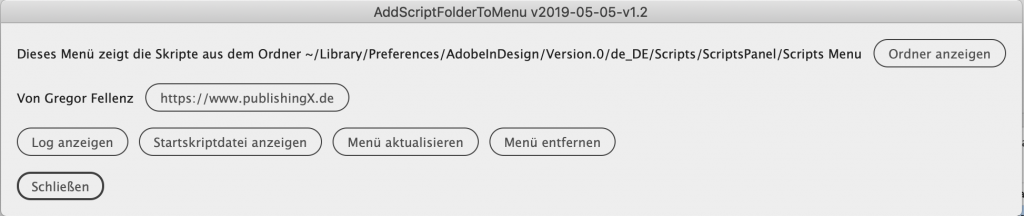
Der unterste Menüpunkt des Menüs ist Über AddScriptFolderToMenu. Aktiviert man diesen, öffnet sich ein Dialog mit folgenden Buttons:
[Ordner anzeigen] Hier kann der Ordner mit den Skripten, die im Menü angzeigt werden, geöffnet werden.
[Log anzeigen] Im Ordner von addScriptFolderToMenu wird ein Ordner „log“ erzeugt, der die Log-Datei enthält. Diese Log-Datei hilft im Supportfall. Der Button öffnet diese Log-Datei.
[Startskriptdatei anzeigen] Dieser Button öffnet den Ordner, in dem das Startup-Skript liegt.
[Menü aktualisieren] Wenn der Inhalt des addScriptFolderToMenu-Ordners verändert wird, wirkt sich dies beim nächsten Öffnen von InDesign aus. Um die Änderung ohne Neustart von InDesign wirksam zu machen klickt man auf diesen Button. Dann wird das addScriptFolderToMenu-Menü aktualisiert.
[Menü entfernen] Dies entfernt das Menü aus InDesign
Zusätzliche Optionen
Startup Skript
In dieser Zeile im Startupskript kann man den Namen des Menüs in InDesign definieren.
Zum Beispiel
scriptMenuName: localize({ en: "Chris-Scripts", de: "Chris-Skripte" }),
In dieser Zeile im Startupskript kann man die Position des Menüs in InDesign definieren. Bei Position „table“ erscheint das Menü hinter dem Menüpunkt „Tabelle“.
Zum Beispiel
position: "table", // help
Separator
Um das Menü zu strukturieren, kann man Separatoren einfügen. Das sind dünne graue Linien, wie man sie aus Programmmenüs kennt. Diese erzeugt man im addScriptFolderToMenu-Menü über Textdateien, die diesen Dateinamen haben: separator-----.txt. Natürlich kann man auch diese Dateien über vorangestellte Nummern im Menü organisieren. Also zum Beispiel 80_separator-----.txt.
Eigentlich ein alter Hut: Web- und Mail-Adressen sollten in InDesign als aktive Hyperlinks ausgezeichnet werden, damit diese im PDF oder eBook anklickbar sind und so vom Nutzer auch tatsächlich verwendet werden können.
Als netter Nebeneffekt werden eure PDFs (und ggfs. auch E-Books) direkt auch barrierefrei.
Gibt’s schon lange von Adobe, nur funktioniert die Funktion mehr schlecht als recht. Deswegen habe ich meine eigene Funktion als kostenloses Skript zur Verfügung gestellt.
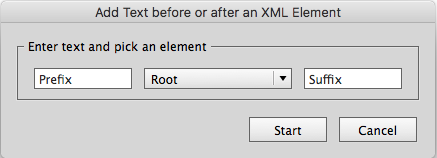
Gibt es eine Möglichkeit in InDesign nach XML-Elementen zu suchen und Text danach einzufügen?
Die Antwort lautet Nein. Eine Anmerkung dazu: Es gibt die Möglichkeit nach Text zu suchen, und den gefundenen Text mit einem XML-Element auszuzeichnen – aber das war ja nicht gefragt.
Die Anforderung fand ich gut und der Code dazu war schon in vielen Skripten im Einsatz, also habe ich schnell das Skript AddTextToXMLElement.jsx gestrickt, dass die Aufgabe löst.
Wie geht das? Ganz einfach: Skript installieren, Skript per Doppelklick ausführen, XML-Element auswählen, Text vor bzw. Nach dem Element eintragen, Start drücken.
Wer andere Default werde benötigt, öffnet das Skript in einem Texteditor und ändert die Zeilen 8–10:
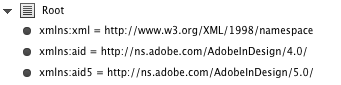
Unter der Hauber werkelt die Funktion evaluateXPathExpression(). Damit diese auch funktioniert, wenn InDesign-Namespaces aktiv sind, werden die Standardnamensräume automatisch hinzugefügt!
An der Stelle sei auch noch mal auf mein uraltes Skript zum Import von XML verwiesen.
In der Praxis ist es oftmals schneller, mehrere einfache GREP-Ersetzungen zu formulieren und hintereinander auszuführen, als lange an einer komplexen Abfrage zu feilen. Wenn die Aufgabe wiederholt ausgeführt werden soll, ist es jedoch mühsam, die einzelnen Abfragen immer wieder herauszusuchen und hintereinander auszuführen.
Ein Skript zur Hilfe
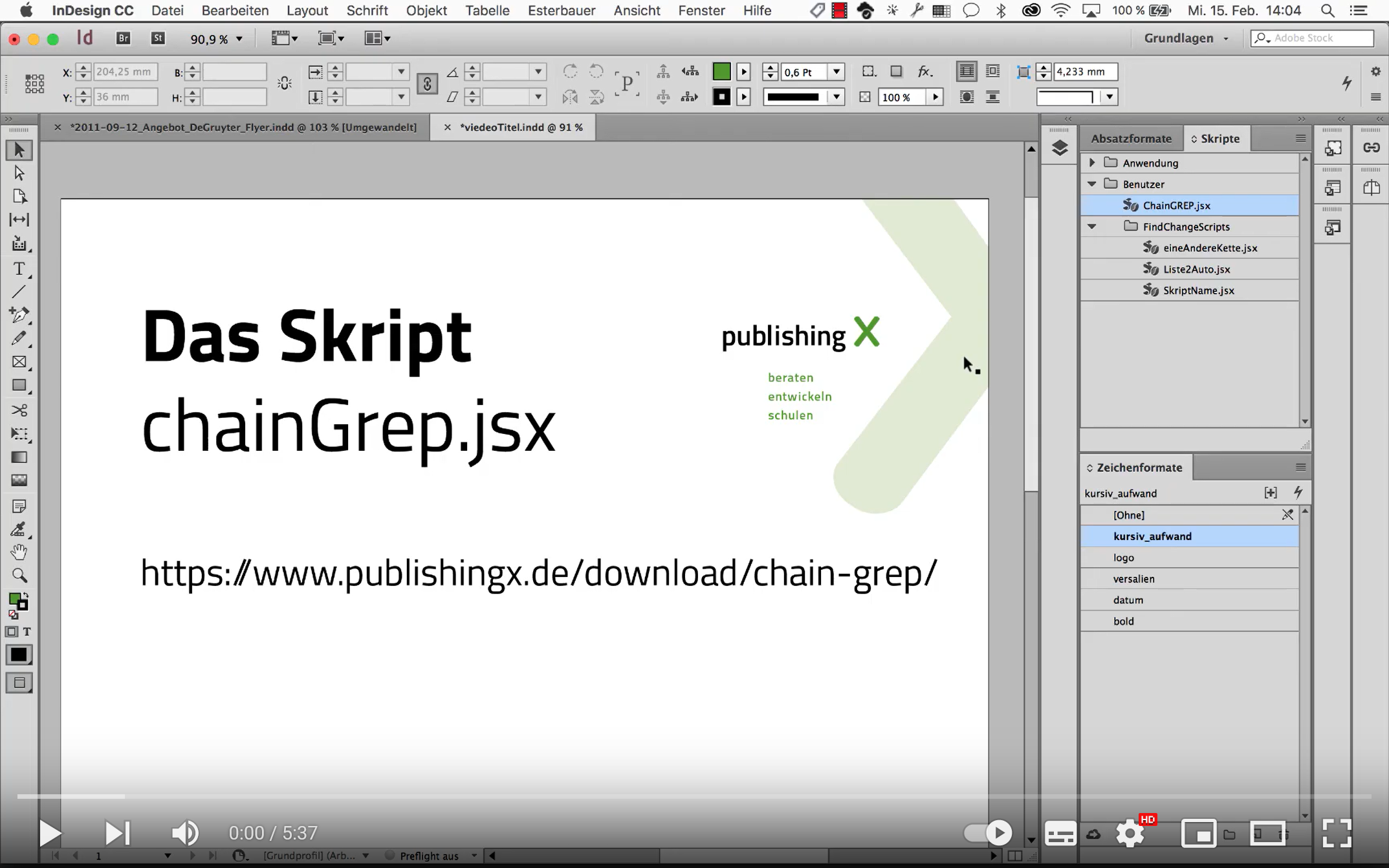
Eine typische Aufgabe für ein Skript – allerdings kann nicht jeder aus dem Stand ein Skript programmieren. Diese Aufgabe erledigt mein kostenloses Skript ChainGREP.jsx: Mit ChainGREP kannst du ein neues Skript erstellen, das mehrere Abfragen hintereinanderlaufen lässt.
Wie geht das?
1. Abfragen erstellen
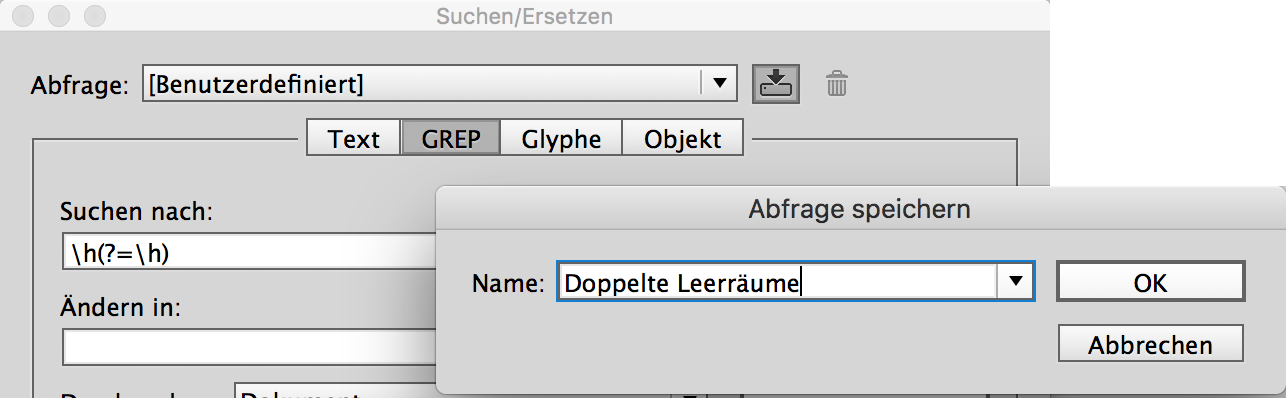
Der erste und wichtigste Schritt ist, die einzelnen GREP-Abfragen im Suchen/Ersetzen-Dialog zu speichern. Dazu erstellst du einfach den gewünschten GREP, ggfs. inklusive der Formateinstellungen, und sicherst ihn mit dem Klick auf das Festplattensymbol. Der Namen sollte die Aufgabe des GREPs möglichst gut beschreiben und wird später für die Auswahl der Abfragen benötigt.
2. Skript herunterladen
Nach dem Download des Skripts musst du das Skript installieren. Wenn du das noch nicht gemacht hast, empfehle ich eine längere Installationsanleitung auf deutsch oder englisch. Als kurze Erinnerung, es ist ganz einfach: Bedienfeld Skripte öffnen; Rechte Maustaste und Im Finder/Explorer öffnen wählen; Skript in den Ordner Scripts Panel kopieren; Fertig.
3. Skript aufrufen
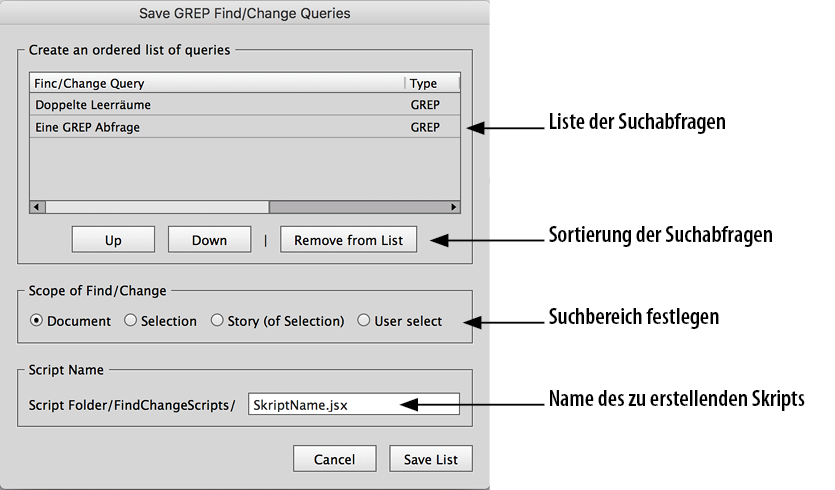
Nach dem Aufruf des Skripts aus der Skriptpalette per Doppelklick erscheint ein Dialog, in dem alle GREP-Abfragen von InDesign angezeigt werden.
Die Liste kann komplett in einem Skript gespeichert werden. Meistens will man aber nur eine gewisse Auswahl an Abfragen hintereinander ablaufen lassen. Dazu kannst du mit Remove Abfragen aus der Auswahl entfernen und die Liste mit den Tasten Up bzw. Down sortieren. Nachdem du deine Auswahl getroffen hast, musst du noch den Suchbereich für das neues Skript im Bereich Scope of Find/Change festlegen. In den meisten Fällen ist die Suche im gesamten Dokument eine gute Wahl.
Nun musst du noch den Namen für das zu speichernde Skript eintragen.
Abschließend drückst du auf Save List und das neue Skript wird im Unterordner FindChangeScripts, der neben dem Skript erstellt wird, gespeichert.
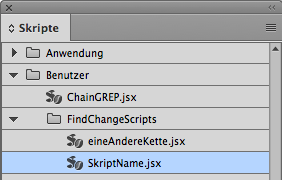
Leider erscheint das Skript unter InDesign CC nicht immer automatisch, manchmal muss man das Skripte-Bedienfeld einmal schließen und wieder öffnen. Dann wird das neue Skript aber sicher angezeigt.
Das neue GREP-Skript kann jetzt widerum per Doppelklick aufgerufen werden. Im Skript werden die Abfragen mit allen Einstellungen abgespeichert. Das heißt, du kannst das Skript auch an einem anderen Computer verwenden, an dem die Abfragen nicht installiert sind. Dies bedeutet aber auch, dass bei einer Veränderung der ursprünglichen GREP-Abfrage das Skript neu erstellt werden muss.
Zum Schluß noch vielen Dank an Peter Kahrel, der mir mit seinem Skript GREP query manager die Idee zu diesem Skript geliefert hat.
Diese Webseite verwendet Cookies. Cookies werden von Wordpress zur Benutzerführung verwendet und helfen dabei, diese Webseite besser zu machen. DatenschutzerklärungAkzeptierenReject
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.